Fraunhofer-Institut für Produktionstechnologie IPT
Fraunhofer-Institut für Produktionstechnologie IPTVollständige Vernetzung im Labor
Wie steht es um die Digitalisierung und Vernetzung im Labor?
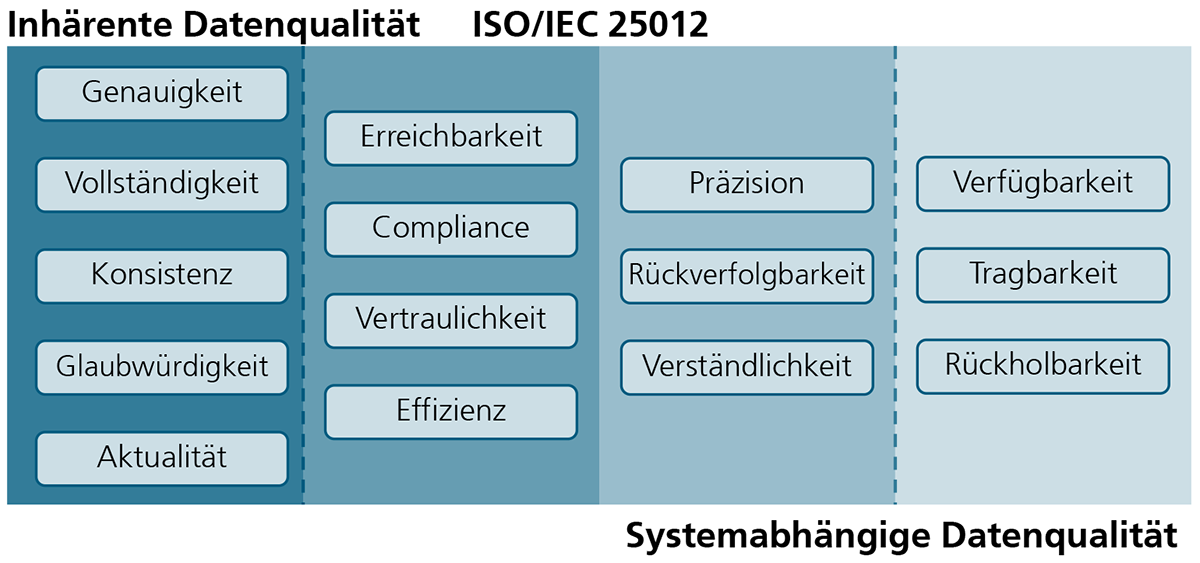
Die Bedeutung der Digitalisierung und Vernetzung im Labor nimmt in den Lebenswissenschaften immer weiter zu. Dank moderner Technologien gelingt es, Geräte miteinander zu verknüpfen, Daten auszutauschen und Arbeitsabläufe zu automatisieren. Die umfassende Vernetzung erlaubt eine effizientere Überwachung und Steuerung der Laborprozesse. Außerdem trägt sie einer höheren Datenintegrität bei, die mehr Transparenz und Nachvollziehbarkeit schafft und eine durchgängige Qualitätssicherung ermöglicht.
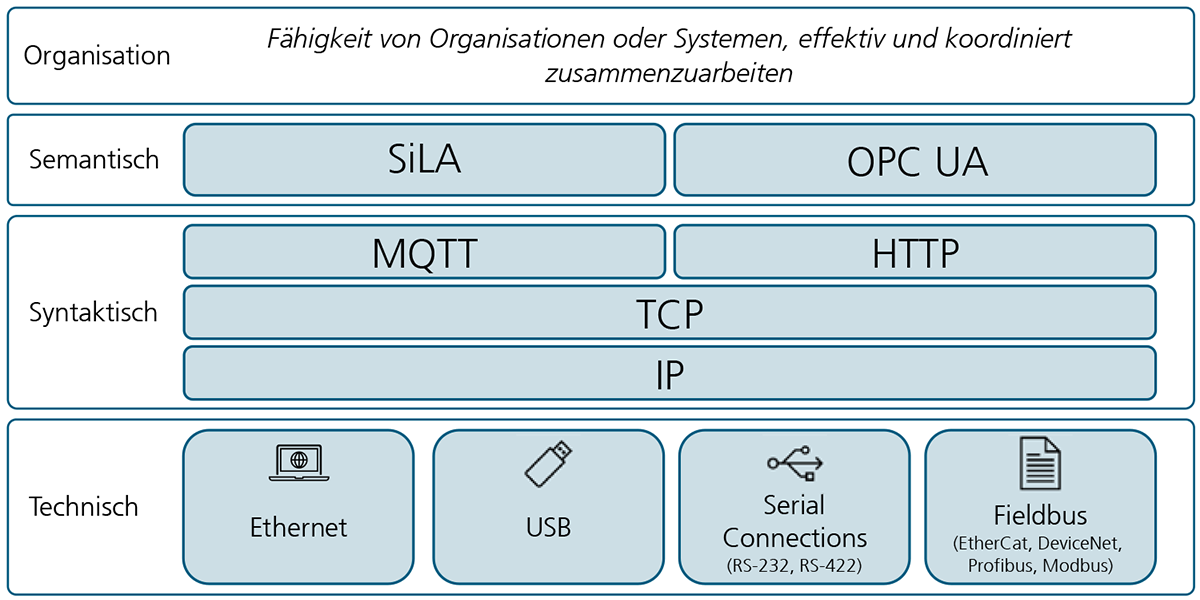
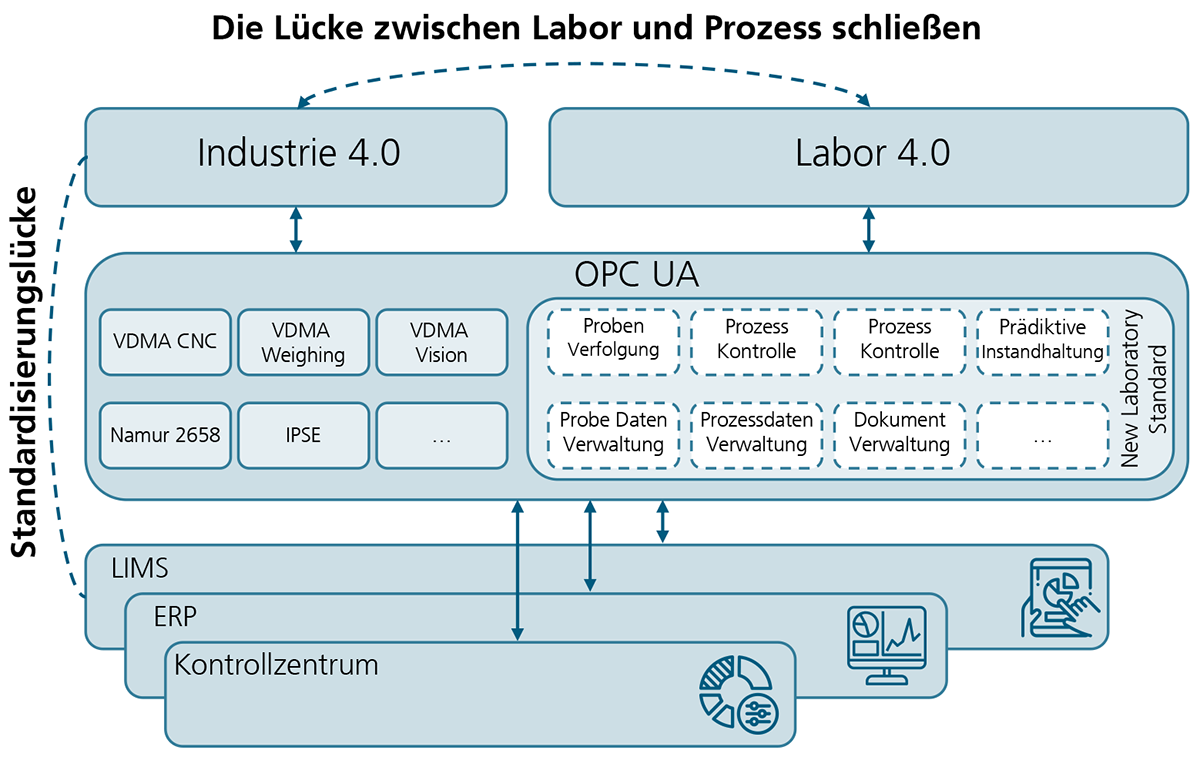
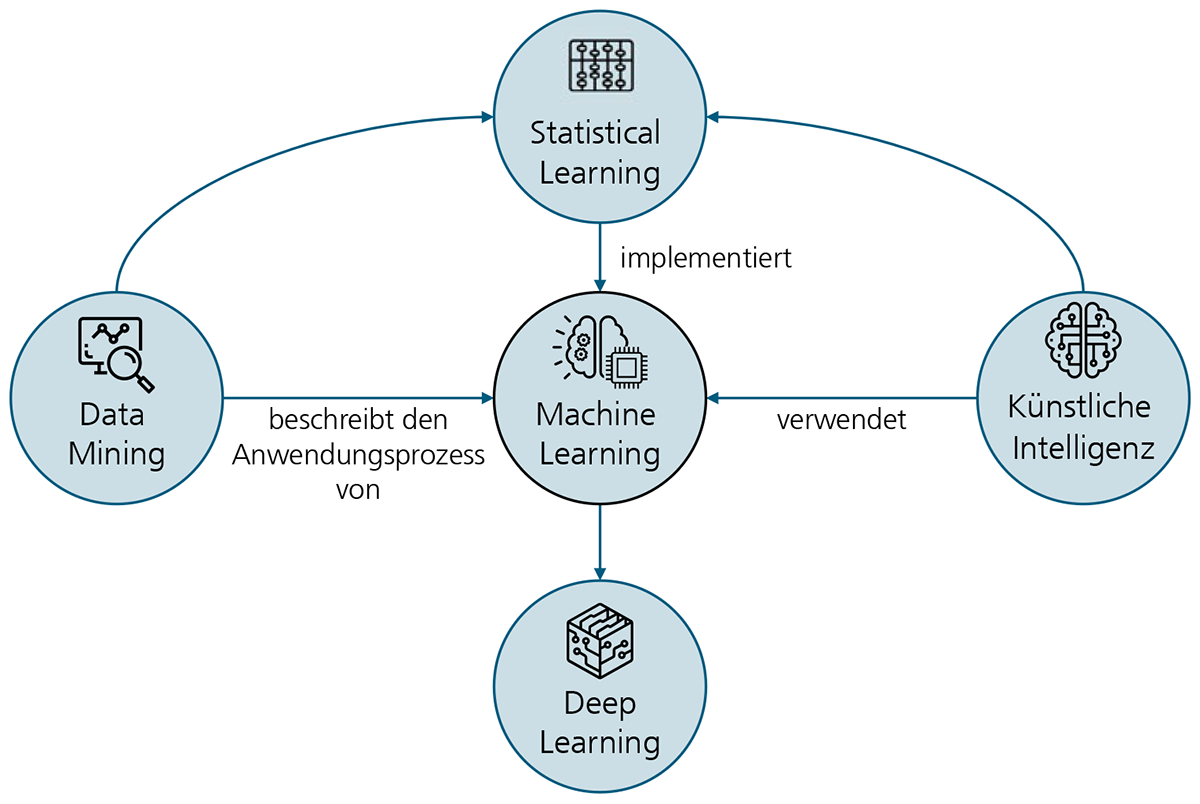
Digitalisierung und Vernetzung im Labor bieten den Lebenswissenschaften Potenzial für den Einsatz neuer Technologien, wie beispielsweise automatisierte KI-getriebene Screeningverfahren, die in der Biotechnologie die Entwicklung neuer Wirkstoffe beschleunigen kann [1], [2]. Heute herrscht in den meisten Laboren eine vielfältige Geräteausstattung verschiedener Hersteller, die nur begrenzt durch elektronische Unterstützung harmonisiert werden kann. Das Zusammenführen und Kontextualisieren der erzeugten Daten gestaltet sich daher kompliziert, fehleranfällig und zeitaufwändig. Deshalb wird eine Vielzahl der Labortätigkeiten heute immer noch manuell durchgeführt. Anstatt die Daten elektronisch zu integrieren, werden Ergebnisse und Messdaten von den Geräten in Systeme zumeist immer noch manuell übertragen. Doch mit zunehmender Anzahl der manuellen Schritte steigt die Wahrscheinlichkeit von Fehlern in den Daten [1], [2]. Wie aber lässt sich die Laborvernetzung und der Datenaustausch zwischen Laboren, individuellen Geräten und vorhandenen Softwarelösungen praktisch umsetzen?